LLMOps - a roadmap for building out LangOps
LLMOps Course Overview
As a localization engineer working with artificial intelligence, I recently completed a training course on LLM (Large Language Model) applications offered by deeplearning.ai about LLMOps. This course was an eye-opener, providing me with a comprehensive understanding of how LLM applications are structured and how they function. Here, I’d like to share some insights from my experience.
Understanding the Structure of LLM Applications
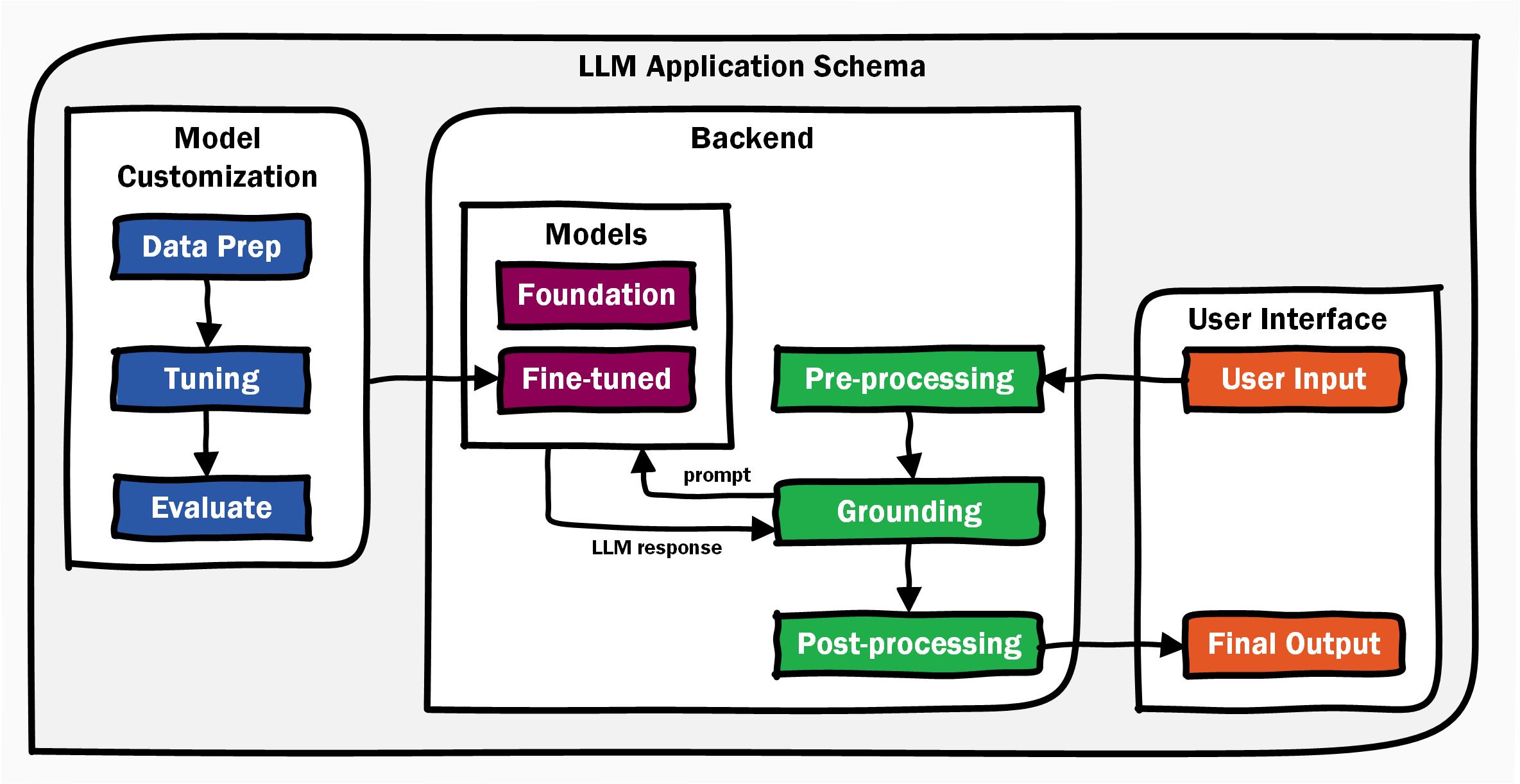
An LLM application is a sophisticated system that begins with the user interface. This is the point where users input their data, whether it be a question, a command, or any other form of interaction. The user interface is designed to be intuitive, ensuring that users can easily communicate with the application.
Once the data is inputted, it is sent to the backend, where the real magic happens. The backend process can be broken down into three critical steps: pre-processing, grounding, and post-processing.
The Backend Process
-
Pre-processing: This initial step involves cleaning and preparing the input data. It ensures that the data is in the right format and context for the model to understand. This might include tasks like tokenization, normalization, and filtering out irrelevant information.
-
Grounding: In this step, we ensure that the LLM has enough information to produce an output that is relevant and accurate. Grounding your LLM in some facts allows you to include some facts along with your prompt that’s provided to the LLM. After the LLM returns the response, you may want to do some more grounding.
-
Post-processing: After the model generates a response, it goes through post-processing. This includes practicing Responsible AI, checking the response for toxicity or bias. Post-processing ensures that only appropriate responses are returned.
Finally, the processed response is sent back to the user interface, where it is displayed as the final output. This seamless flow from input to output is what makes LLM applications so powerful and user-friendly.
Customizing a Model: The Path to Fine-Tuning
One of the most exciting aspects of working with LLMs is the ability to customize models to better suit specific applications. This involves three key steps: data preparation, tuning, and evaluation.
-
Data Preparation: This step involves gathering and organizing the data that will be used to train the model. The quality and relevance of this data are crucial, as they directly impact the model’s performance.
-
Tuning: Once the data is ready, the model undergoes tuning. This process involves adjusting the model’s parameters and training it on the prepared data. The goal is to enhance the model’s ability to perform specific tasks or understand particular contexts.
-
Evaluation: After tuning, the model is evaluated to ensure it meets the desired performance standards. This involves testing the model with various inputs and measuring its accuracy, efficiency, and reliability.
By following these steps, a model can be fine-tuned to deliver more precise and contextually relevant responses, making it a valuable tool for specialized applications.
Orchestration and Automation
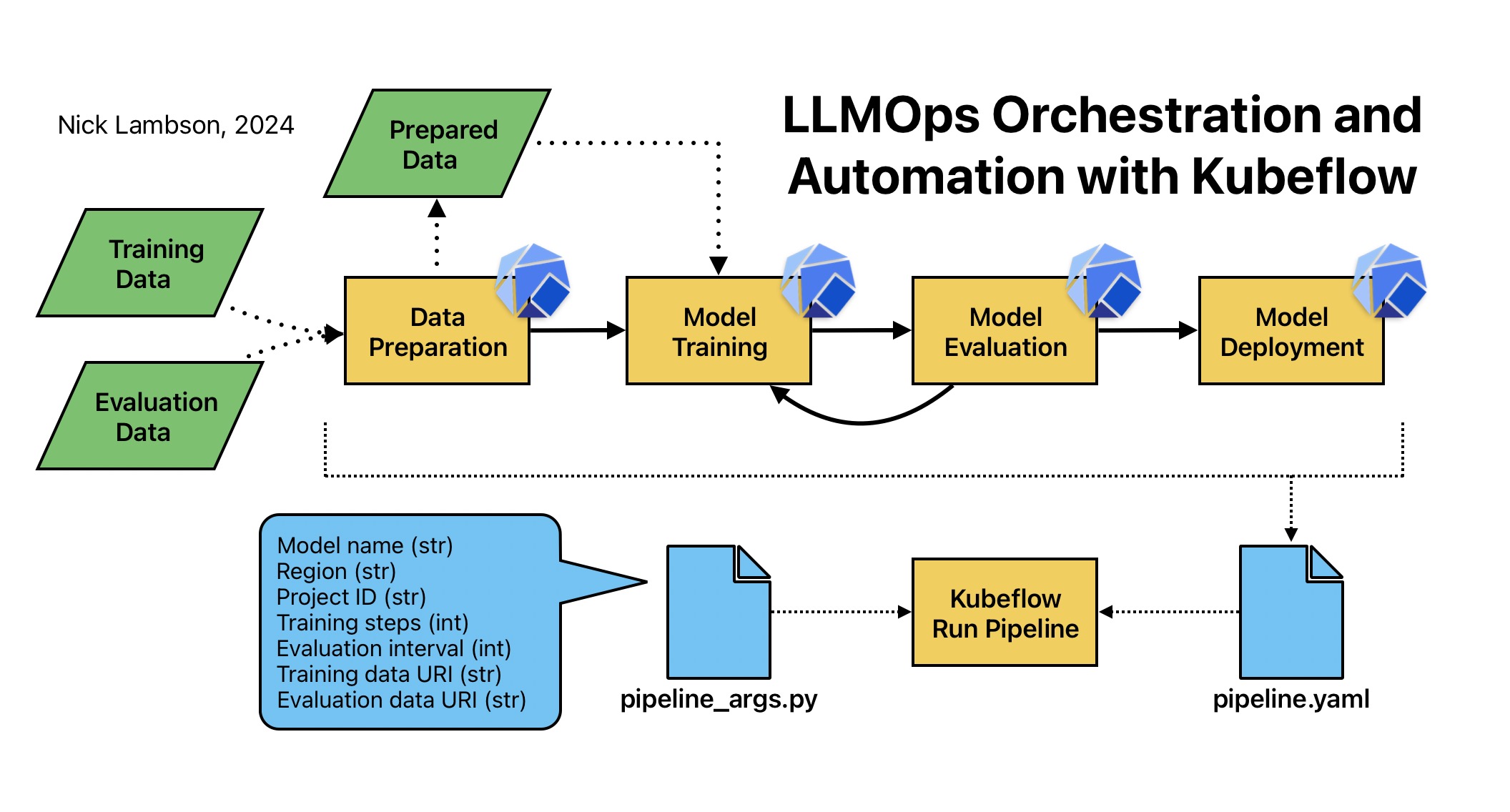
The process of preparing data, training a model, evaluating its output, and deploying it to production can be labor-intensive and time-consuming. Orchestration means designing the steps of a machine learning pipeline and automation means setting up the pipeline to execute without the need for human involvement.
Kubeflow
Kubeflow is an open-source tool that integrates with Python and helps developers orchestrate and automate machine learning pipelines. It leverages Kubernetes to manage and deploy these workflows, ensuring scalability and consistency across different environments. With Kubeflow, you can set up workflows using a straightforward language called a domain-specific language (DSL). Using Kubeflow to orchestrate and automate machine learning pipelines is a best practice because it simplifies the management of complex workflows, ensures consistency across different environments using Kubernetes, and allows data scientists to focus on model improvement rather than infrastructure concerns.
Orchestration
Orchestration of pipeline steps is done by designating Python functions as Kubeflow components. These components are then linked together to form a complete workflow, allowing for seamless integration and execution of each step in the machine learning pipeline. This approach enhances modularity, reusability, and scalability. Once orchestration of the pipeline steps is complete, the pipeline is exported to a pipeline.yaml file, which serves as a blueprint for deploying the workflow across various environments.
Automation
To execute the pipeline, you only need to provide pipeline arguments, typically in the form of a Python dictionary or a JSON file. These arguments specify essential details required for the pipeline’s operation, such as the URI paths for both training and evaluation data, the model’s name, and the deployment region. By clearly defining these parameters, the pipeline can be efficiently run, ensuring that all necessary resources and configurations are in place for successful execution.
By modularizing the pipeline steps with Kubeflow and externalizing the pipeline arguments, the work of the developer can be automated. This setup allows for the pipeline to be executed automatically and even scheduled to run at regular intervals, ensuring continuous integration and deployment without manual intervention.
Conclusion
Taking the deeplearning.ai course on LLM applications was a valuable experience. It taught me how to build and customize LLM applications, as well as orchestrate and automate machine learning pipelines. I’m eager to use what I’ve learned in future projects and further explore the potential of LLMs in localization.